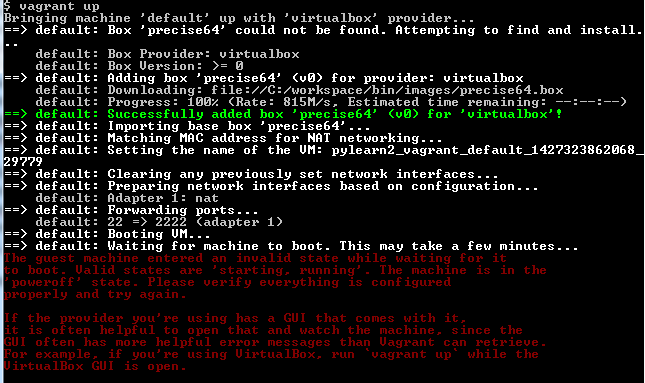
Курсы, которые я прошел
Однажды мне очень сильно повезло и у меня появилось 9 относительно спокойных месяцев, когда выходные и нерабочие вечера чаще проводишь дома и никаких дальних поездок, курортов и прочих развлечений даже не планируешь. Я решил потратить это время с максимальной пользой для себя, тем более что после этого 9-ти месячного периода жизнь кардинально изменилась и свободного времени заметно поубавилось. Но это уже другая история :).
Я решил испопробовать массовое онлайн обучение (или MOOC) что называется "по максимуму". Всего удалось пройти чуть более 10 курсов, и, после двухгодичного перерыва многое стало забываться, посему и решил немого вспомнить как это было. Сейчас пока первые пару курсов "вспомнил", потом буду докидывать еще.
Стратегия прохождения
Я записывался на несколько курсов одновременно и не очень сопротивлялся соблазну подписываться на "все и сразу". Это же нереально круто, когда преподы из самого Standford, Princeton или Berkeley выкладывают свои курсы онлайн абсолютно бесплатно, причем программа курса зачастую такая же как и для студентов именитых университетов! Естественно, что пройти "все и сразу" невозможно и после первых недели-двух я определялся стоит ли продолжать слушать курс или лучше переключиться на другие. В процессе такого "естественного отбора" я обнаружил, что моя пропускная способность - это 2, максимум 3 параллельных курса, которые я планировал пройти до конца.Конспектирование
Оказалось очень удобно после 3х лет пролистать конспект и вспомнить детали, просмотреть слайды и видео лекций. Кстати, на экзаменах конспект тоже иногда помогал. В качестве инструмента конспектирования и использовал XMind. В mind map я приатачивал слайды и видео лекций, иногда вставлял свои пометки. Примерно так:
Дальше я буду описывать курсы, которые прошли такую фильтрацию.
В разделе "о чем курс" сугубо моя личная отсебятина, которая не всегда совпадает с официальной версией.
Heterogeneous Parallel Programming

Страница курса: https://www.coursera.org/course/hetero
Университет: University of Illinois at Urbana-Champaign
Сложность: 3
Первый курс, который я прошел на курсере, поэтому он возглавляет мой список самых интересных курсов. Причем очень даже заслуженно :)
О чем курс
Мы как-то очень привыкли к старым добрым однопоточным машинам, прототипом которых была машина Тьюринга. Тьюринговская лента (или "нить" - thread) всего одна и поэтому нет проблем с переплетениями нескольких лент во время работы. По сути первые компьютеры и были такими себе одноленточными реализациями машины Тьюринга. Потом, в процессе эволюции, возникла необходимость делить процессорное время между несколькими операторами, для чего увеличивали мощьность процессорных устройств, повышали частоту, появились RISC процессоры, конвейерная обработка команд, процессорный кеш и много-много других усовершенствований, о которых 99.99% людей, пользующихся компьютерами даже не догадываются. В общем, однопоточные процессоры делались все сильнее, быстрее, совершеннее и отлично подходят для задач, где надо выполнять действия последовательно. Но что если такой подход неэффективен для ряда задач? Что если заменить несколько "одноленточных" суперпроцессоров на несколько тысяч не таких супер, но все же реально параллельных процессоров? Какие задачи тогда можно решать быстрее?Задача из курса.
Предположим есть очень длинная палка колбасы (несколько км длиной), за которой стоит длинная очередь в сотни (а может и тысячи) людей. Каждый человек говорит какой длины кусок ему надо отрезать.
Традиционное последовательное решение было бы таким: каждый по очереди подходит и ему отрезают кусок такой длины, какой скажет. Понятно, что для очереди длиной, например, в миллиард, мы бы занимались этим очень долго.
Можно ли сразу у всех спросить длину отрезка, нанести разметку и, имея несколько тысяч ножей, сразу разрезать так как надо?
В этом курсе мы практиковались в решении подобного рода задач с использованием GPU, узнали много нового о многопроцессорной архитектуре. Задания надо было реализовывать на C с использованием CUDA SDK. У кого не было возможности отлаживать код локально (т.к. надо GPU от NVIDIA), те могли загружать код прямо из браузерного окна редактирования и дебажить способом просмотра логов. Форум был очень активен и там часто можно было найти подсказки на решения проблем. Очень жаль, что этот курс был всего один раз и непонятно будет ли повторяться, но есть похожий курс на Udacity.
Discrete Optimization
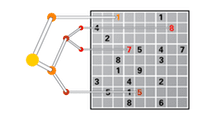
Страница курса: https://www.coursera.org/course/optimization
Университет: The University of Melbourne
Сложность: 4.9
Как только я посмотрел интродактори видео я понял, что будет очень интересно и не ошибся. Профессор оказался еще тем гиком. Я вот даже не поленился добавить это интродактари видео:
О чем курс
Сколько надо цветов, чтобы раскрасить карту так, чтобы соседние государства не были окрашены в одинаковый цвет? А если государств 1000 или 10000?
По какому маршруту должна ездить фура чтобы развезти продукты по нескольким магазинам и потратить как можно меньше горючего/времени? А если магазинов 1000, а фур всего 10?
Классическая задача комивояжера - как найти оптимальное решение для 10 городов? А для 100? А для 1000? А вообще возможно ли его найти за относительно небольшое время? А если нет, то как можно максимально приблизиться к оптимальному решению?
Вот такие задачи мы учились решать в рамках курса. Оказывается есть довольно много инструментов, которые успешно применяются для задач оптимизации. Это и constraint programming и алгоритмы локального поиска (local search), и линейное программирование (linear programming), и целочисленное программирование. (integer programming)
Практические задачи были разделены на 5 уровней сложности. Для каждого уровня свой набор входных данных. Например, для задачи комивояжера для уровня 1 было до 10 городов, для 2го от 10 до 50, для 3-го от 100 до 200, 4й -500 - 1000 и для 5-го более 50тыс. Если первые пару уровней обычно можно было решить простым перебором, то начиная с 3го все становилось очень интересно. Естественно, чтобы получить сертификат нужно было решить все задачи как минимум 3го уровня сложности, а для сертификата с отличием (with distinction) - 4го и 5го.
Попробовал тулы
- SCIP optimizer http://scip.zib.de/. Простой и быстрый оптимизатор, оптимизирует задачи с помощью constraint programming и linear-integer programming. Поддерживает стандарт языка ZIMPL. Очень хорошо ломает мозг.
- GLPK solver: http://www.gnu.org/software/glpk/. Изначально я пробовал его для некоторых задач, но потом перешел на SCIP, не помню почему
- Много кодил на Java :). Задачу комивояжера, например, оптимизировал с помощью алгоритма K-opt (local search) и Simulated annealing для поиска глобального минимума.
Практические задачи были разделены на 5 уровней сложности. Для каждого уровня свой набор входных данных. Например, для задачи комивояжера для уровня 1 было до 10 городов, для 2го от 10 до 50, для 3-го от 100 до 200, 4й -500 - 1000 и для 5-го более 50тыс. Если первые пару уровней обычно можно было решить простым перебором, то начиная с 3го все становилось очень интересно. Естественно, чтобы получить сертификат нужно было решить все задачи как минимум 3го уровня сложности, а для сертификата с отличием (with distinction) - 4го и 5го.
Попробовал тулы
- SCIP optimizer http://scip.zib.de/. Простой и быстрый оптимизатор, оптимизирует задачи с помощью constraint programming и linear-integer programming. Поддерживает стандарт языка ZIMPL. Очень хорошо ломает мозг.
- GLPK solver: http://www.gnu.org/software/glpk/. Изначально я пробовал его для некоторых задач, но потом перешел на SCIP, не помню почему
- Много кодил на Java :). Задачу комивояжера, например, оптимизировал с помощью алгоритма K-opt (local search) и Simulated annealing для поиска глобального минимума.