В прошлом посте я обещал расшарить результаты своего ночного кодинга, так что это вроде как продолжение (практическая часть). Здесь уже будет технический хардкор на Java.
Гугл говорит, что более 1млн:

Если считать только количество unigram (уникальных слов), то это не проблема хранить 1млн счетчиков в памяти, но как только понядобятся 2-,3-..грамы, то требования к памяти совсем другие. Для bigram в худшем случае понадобится хранить \(1млн^2\) каунтеров, для trigram \(1млн^3\) и т.д.
Хотелось бы обойтись без всяких DB/NoSQL и прочих Hadoop'ов, поскольку это сильно утяжелит решение. Я начну с чего-то простого, но достаточно эффективного по памяти.
Поясню на примере.
Возьмем предложения "The dog likes the cat" и "the cat hates the dog".
Вот как будет выглядеть Trie после того, как посчитаю количество биграм для этих 2х предложений:

Все слова приводятся к нижнему регистру, знаки препинания и прочие нетерминальные символы я решил отбросить.




Оцениваем сложность по пямяти
Для начала надо было придумать как посчитать сколько раз встречаютсы все эти "the", "the cat", "the cat likes" и т.д. Уникальных слов будет много, а уникальных bi-,tri-, и.т.д -gramm будет еще больше. Для каждой n-gramm'ы нужно хранить сколько раз она встречается в тексте. Чтобы примерно оценить масштаб проблемы я предварительно спросил у гугла "сколько слов в английском языке?"Гугл говорит, что более 1млн:
Если считать только количество unigram (уникальных слов), то это не проблема хранить 1млн счетчиков в памяти, но как только понядобятся 2-,3-..грамы, то требования к памяти совсем другие. Для bigram в худшем случае понадобится хранить \(1млн^2\) каунтеров, для trigram \(1млн^3\) и т.д.
Хотелось бы обойтись без всяких DB/NoSQL и прочих Hadoop'ов, поскольку это сильно утяжелит решение. Я начну с чего-то простого, но достаточно эффективного по памяти.
Структура данных Trie
Попробую использовать структуру данных Trie (хороший пример можно также посмотреть здесь). В моем случае Trie будет все тем же деревом, где каждый узел представляет слово, а дочки-возможные варианты слов, которые следуют за ним.Поясню на примере.
Возьмем предложения "The dog likes the cat" и "the cat hates the dog".
Вот как будет выглядеть Trie после того, как посчитаю количество биграм для этих 2х предложений:
По дереву легко можно найти, например, что слово "the" встречается 4 раза, а "the dog" - 1 раз. Слово "dog" - 2 раза, а "dog likes" - 1 и т.д. При увеличении "N-грамности" дерево будет содержать новые уровни. Количество уровней в trie будет равно числу N в N-Gram'е (рутовую ноду я не считаю).
Пишу код
Сам код здесь не буду постить, для этого есть гитхаб:https://github.com/szelenin/kaggle/tree/master/billion-word-imputation. Укажу лишь, что но начал я с такого теста:
А закончил таким:
Все слова приводятся к нижнему регистру, знаки препинания и прочие нетерминальные символы я решил отбросить.
Пробный пуск
Для начала я запустил подсчет уникальных слов, чтобы получить общую статистику по тренировочному файлу. Вот что выдала после 2х с небольшим минут.
Lines read: 30301028. Unique words: 1026207, total words: 693467918
Количество уникальных слов практически такое же как выдал гугл. Так что, думаю, все возможные слова, которые есть в английском языке присутствуют :)
Lines read: 30301028. Unique words: 1026207, total words: 693467918
Количество уникальных слов практически такое же как выдал гугл. Так что, думаю, все возможные слова, которые есть в английском языке присутствуют :)
1й запуск для подсчета триграм
Я особенно не расчитывал, что моя считалка посчитает количество всех возможных триграм в тексте, просто интересно через сколько времени закончится память :). Память закончилась практически сразу и JVM вывалился с жуткой ошибкой:
# A fatal error has been detected by the Java Runtime Environment:
#
# EXCEPTION_ACCESS_VIOLATION (0xc0000005) at pc=0x000000006f533c0b, pid=4768, tid=6776
#
# JRE version: Java(TM) SE Runtime Environment (8.0_20-b26) (build 1.8.0_20-b26)
2й запуск
На второй запуск я выделил 12Гб под JVM и запустил jvisualvm чтобы посмотреть как кушается память. Проработала программка 4минуты и вывалилась с такой же ошибкой. Но все таки успела прочитать 3.6 млн строк, в которых было 83.5 млн слов, из которых почти 400 тыс уникальных, что в общем-то неплохо для 4х минут работы :) :
Lines read: 3648300. Unique words: 398484, total words: 83500620
Вот как заполнялась память
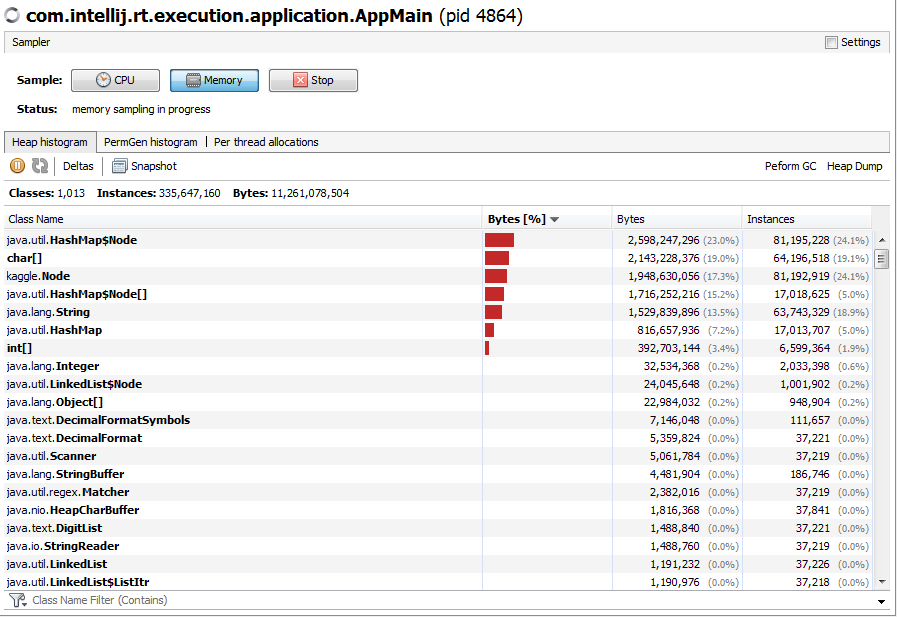
А вот какие обьекты наиболее активно ее наполняли:
Глядя на количество инстансов HashMap я решил немного сэкономить и чуть оптимизировать код. Дело в том, что в каждой ноде я по умолчанию создавал мапу для ее детей:
Но для последнего уровня дерева детей не предполагается, поэтому можно мапу не создавать.
3й запуск
Сделал создание мапы с детьми lazy и запустил еще раз. На этот раз работало 30 минут, после чего я убил процесс, т.к. дожидаться правильного OutOfMemory совсем не хотелось. Перед смертью считалка отчиталась, что прочитала 7.1 млн предложений из 16.2млн слов, из которых 541тыс уникальных.
Lines read: 7119000. Unique words: 541538, total words: 162929078

Lines read: 7119000. Unique words: 541538, total words: 162929078
Вот график поедания памяти
А вот ее содержимое
Выводы
Считалка свободно просчитывает 4млн предложений за 4минуты. В тренировочном наборе всего 30млн. Можно, конечно, придумывать новые способы хранения счетчиков, подключать внешние хранилища данных, и т.д. но это может превратиться в бесконечный процесс. Хотелось бы закончить с начальной версии модели, а затем ее усовершенствовать в плане производительности. Поэтому я разобью тренировочный набор на 10 частей и буду работать с ними отдельно. Еще надо найти где пропущено слово и, самое сложное, какое слово вместо него нужно добавить. Так что буду отлаживать модель на одном из 10 наборов или на каждом по очереди, а затем будем думать как обьеденить.
PS
Как говорится "быстро сказка сказывается, но не быстро дело делается". На следующий день я бодренько поправил код, который разбивает тренировочный набор на 10 частей, считает каунтеры и сохраняет расчитанные значения в файле. Запустил прогу и через 30 минут она вывалилась с таким же ACCESS VIOLATION как и в 1й раз. Вот так съедалась память во время работы:
Это довольно странно, т.к. после каждой просчитанной порции тренировочного файла GC должен был убрать все что с этой порцией связано. Так что я ожидал увидеть несколько "холмов" в графике.
Ради эксперимента я сказал JVM использовать Garbage Collector GC1 (-XX:+UseG1GC) и запустил считалку опять. На этот раз она упала при сериализации модели, так что я поменял стандартную Java сериализацию на kryo и запустил еще раз. В этот раз все прошло как и ожидалось:
График показывает, что GC корректно убивает ненужные объекты. Тогда почему это не работало раньше, с Garbage collector'ом, по умолчанию?
По умолчанию применяется Concurrent Mark&Sweep GC, который разделяет объекты на "короткоживущие" и "долгоживущие". Область короткоживущих чистится часто, а долгоживущие чистятся гораздо реже. Если JVM положил объект в "долгоживущую" область, то потом его оттуда сложно будет вытащить. По крайней мере в моем случае похоже, что все попытки почистить долгоживущую область заканчивались крашем JVM. GC1 разделяет весь хип на блоки размером от 1 до 32мб. Каждый блок может быть "короткоживущим" или "долгоживущим". Если в блоке все объекты уже не используются, то блок освобождается целиком. Подробнее про устройство GC1 можно посмотреть здесь.
Ресурсы
1. Мой код на гитхабе https://github.com/szelenin/kaggle/tree/master/billion-word-imputation
2. Описание с структуры Trie на википедии: http://en.wikipedia.org/wiki/Trie
3. Описание Trie с примерами : http://www.toptal.com/java/the-trie-a-neglected-data-structure
4. Как устроен GC1 : http://www.infoq.com/articles/G1-One-Garbage-Collector-To-Rule-Them-All
5. Kryo serialization framework : https://github.com/EsotericSoftware/kryo
5. Kryo serialization framework : https://github.com/EsotericSoftware/kryo